本文共 3488 字,大约阅读时间需要 11 分钟。
现如今,随着云计算和分布式的落地和发展,越来越多的服务器都转到云上,微服务架构的落地也让现在的 IT 系统架构越来越复杂。我们的服务、应用所面对的规模也越来越大,这样的需求需要强大的运维管控系统在后面支撑。
智能运维(AIOps)的概念现在很火,旨在借助人工智能机器学习和算法将IT运维人员从繁重的工作中解救出来,但是对于智能运维大家都在探索当中,AIOps的技术并不是很成熟。大多数企业还处在对自动化运维的需求迫在眉睫的阶段,需要运用专业化、标准化和流程化的手段来实现运维工作的自动化管理。因此本次InfoQ记者采访了小米资深架构师孙寅,和大家一起了解小米的自动化运维平台是如何演进的。
背景介绍
小米自动化运维平台从2013年开始建设。截止目前,小米有300+业务线,5W+服务器规模。6年里伴随着互联网业务的陡峭增长,小米运维平台也发生了天翻地覆的变化。平台整体建设情况大致可以分为三个阶段:
1. 工具型平台(2013~2014年)
这个阶段,平台主要在解决一些基础痛点问题,如资产难以管理、软硬件难以有效监控、人肉发布效率低下错误率高等,因此孵化了CMDB+服务树、监控系统(Falcon)、发布系统等几个一直沿用至今的工具型平台的核心组件。并且借助推广这几个核心组件,对业务进行了基础标准化。
2. 体系化平台 (2014~2015年)
在此阶段,团队逐步补齐了整个运维闭环中的各个环节,如预算交付、OS自动安装和环境初始化、域名、负载均衡、备份等。并通过打通运维闭环中的各个环节和体系化设计,建设起了跨越系统的自动化体系,如服务器交付自动初始化、各种场景的监控自动发现、发布和负载均衡变更联动等等。
3. 数据中心操作系统(DCOS)(2016年至今)
在此阶段,以容器PaaS为标准化载体,构建自动化程度更高、能力更丰富、体系更内聚的基础架构生态系统,包括:
监控:丰富细化了各种具体场景的监控,如:
- 公有云、网络设备、南北/东西网络、域名、负载均衡、容器集群等;
- 端到端访问质量监控,模拟用户真实访问发现最后一公里问题;
- 分布式调用跟踪监控,穿透式跟踪故障点;
- 精准报警和根因分析,整合各类型监控,依赖决策树、机器学习等能力自动寻找根因。
服务组件:自助创建集群,自动配置最佳实践,具备故障自愈能力的服务组件,如MySQL、Redis、Memcached、Kafka、ES等;
CI/CD:打通整个开发、测试、交付链条的自动化Pipeline;
服务治理:流量路由、流量镜像、服务保护、白名单、熔断、链路跟踪、服务拓扑;
故障:故障注入、故障自愈、故障跟踪。
平台架构设计
小米自动化运维平台的整个平台体系架构,可参考下面图示:

图示底部是IaaS层的各种资源及其管理平台,如网络管理、多云接入、域名、负载均衡等。
上面承载了庞大的PaaS体系,划分为四大部分,容器、应用、服务治理、故障容灾。
左右两侧是一些公共能力,如CMDB、监控、安全。
配置管理(CMDB)由于和内部资产、环境、流程有比较紧密的耦合关系,业内也并没有比较成熟的开源实现,因此基本完全自研。
部署发布系统使用了Puppet对运行环境进行变更和管理,植入了God为每个进程提供自动恢复的能力,使用了Docker来解决编译一致性的问题,同时也支持了静态发布Docker容器。
小米早期使用了开源监控系统Zabbix,但由于监控规模得扩大、监控场景得复杂化、配置难度大等原因,我们内部自研了监控系统Falcon,也就是业内著名的企业级监控Open-Falcon。随着使用场景得继续丰富,目前也已支持监控数据旁路到ElasticSearch、仪表盘支持Grafana,同时还在探寻数据存储使用时序数据库Beringei,以支持更好的扩展性和便于实现更丰富的报警判别功能。
平台建设的难点
由于整体建设的规划比较清晰,因此并没有比较大的挑战,如果一定要找,可能在于一些魔鬼细节上面。比如:
灵活的服务树设计,并未能解决组织架构频繁变更后带来的树结构混乱,同时因为体系中的各种系统都与服务树有很强的耦合,以致后期不得不想办法构建一棵新的组织结构树,来为服务树“打补丁”;
忽略了服务命名的POSIX规范,以致于一些严格遵守命名规则的开源组件出现了冲突。
标准化的问题,是所有平台体系的共通问题,无标准,不平台。早期平台标准化的主要有三个方向:
服务命名,这个标准主要是通过服务树来完成的,体系中的各种系统也都统一使用相同的服务命名规范,因此服务命名逐渐就成了事实标准;
服务目录,这个标准是通过部署发布系统来规范的,使用该系统的服务,会自动按照相应的规范生成目录。目录的标准化,也继续推进了其他和运行环境有关的自动化系统的演进;
监控方法,这个标准是通过监控系统来实施的,各种类型场景的监控,都以遵循监控系统的监控协议来上报,并可实现为监控系统的插件。
后期在DCOS阶段,由于服务都在容器云内调度,运行环境高度内聚,很多标准可以由平台自动生成,标准化也就因此变得更加容易。
整个平台体系的设计思路一以贯之,各个系统间有很多联合设计,以完成更长路径的自动化,而不仅仅解决每一个原子事务的自动化。例如:
预算交付系统,和服务树、监控系统配合,达到自动监控基础监控项的能力;
域名系统、负载均衡系统、云对接系统、发布系统配合,达到自动配置管理接入层的能力;
还有,动态CMDB、分布式跟踪、决策树配合,得到故障精准定位能力。
平台实践
小米的自动化运维平台主要指的是容器云平台。众所周知,基于Docker、Mesos、kubernetes等开源组件实现的容器云平台,天生具有资源编排能力,对无状态应用的扩容也无比简单。
资源协调方面,我们增加了基于LVM的磁盘空间资源,以及基于tc模拟的带宽控制资源,用于更精细化控制容器间的资源隔离。
扩容能力方面,小米的实现有一些时代的烙印,也有一些巧妙之处值得借鉴:
早期使用Mesos的Batch任务框架Chronos,来实现定时扩缩容能力。这种方式比较巧妙地解决了实现定时难以解决的分布式容错问题;
用Falcon的集群监控策略+触发钩子,作为自动扩缩容的条件,这样继承了业务已有的监控指标和监控策略,同时还可自动作为抑制报警的条件。
举例说明这种方案的联动效果:
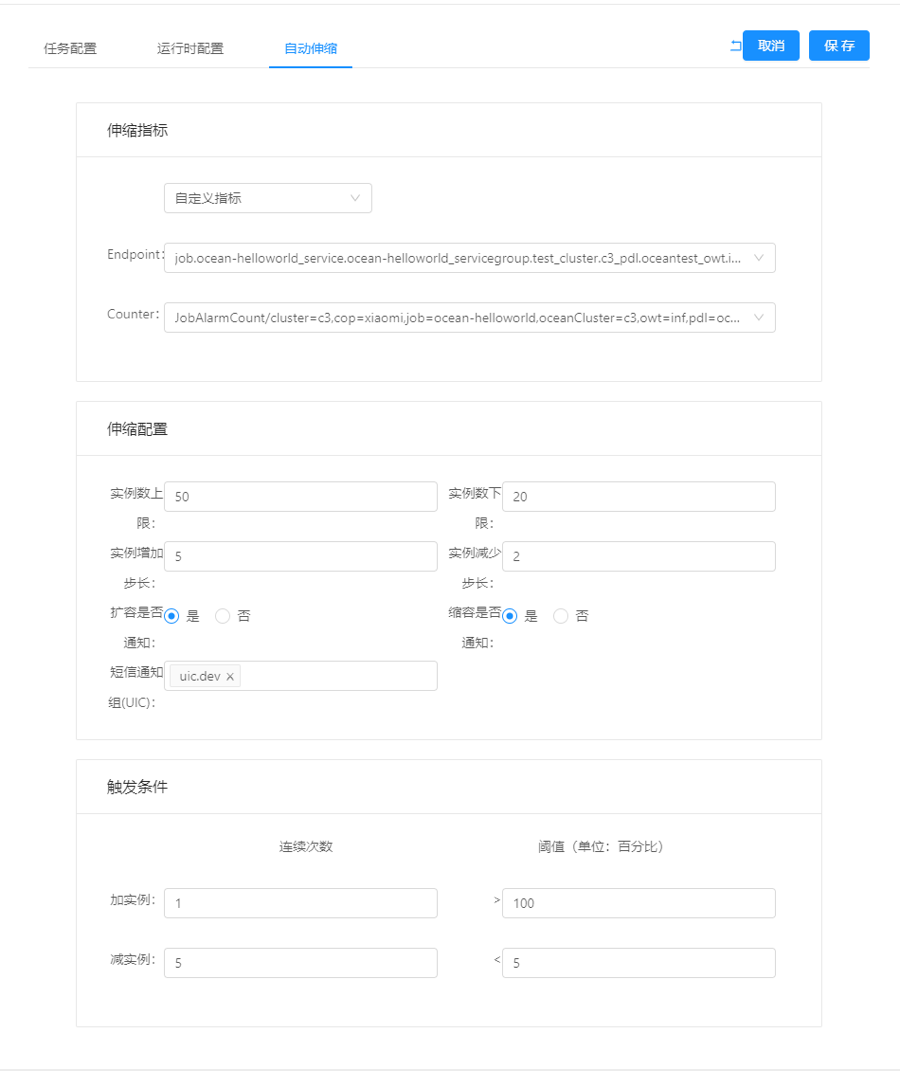
上图为某服务的自动扩缩配置,由于业务代码按照监控标准,已上报了JobAlarmCount指标,因此系统可与监控系统对接,直接使用该指标自动生成集群监控策略,并以此作为自动扩缩容的触发条件。
该例中当JobAlarmCount的集群平均值连续1次大于100,就触发扩容,每次扩容5个实例,当连续5次小于5,就触发缩容,每次缩容2个实例。每次触发扩缩容,都通过报警机制发送到uic.dev报警组,同时扩缩容的上下限,分别是50和20。
这样的自动扩缩容配置,可以在业务出现容量问题时,快速(连续2次)触发扩容,当业务恢复正常后,平缓触发缩容。同时实例数量的上下限,用于保护资源和业务的可靠性。
小米自动化运维的技术探索
前沿技术方面,小米自动化运维目前主要在探索这样几个方向:
混沌工程:对于每天层出不穷的可靠性问题,依靠人(SRE)的经验每天去排除,是既不靠谱也不经济的方式。混沌工程是把经验转化为探索规则,对在线系统进行或计划或随机的应用探索,来学习观察系统的反应,以发现系统不可靠因素的工程体系;
Service Mesh(服务网格):通过把RPC框架可以完成的功能,下沉到基础设施层,以便统一迭代建设,同时解决多语言栈难以统一的痛点;
故障精准报警(根因分析):业内有工程和机器学习两个流派,我们选择工程派,用动态CMDB+分布式跟踪+决策树来寻找根因;
故障自愈:在根因分析的基础上,通过构建灵活的预案构筑框架,逐步提升可故障自愈的比例。
写在最后
结合小米几年间自动化运维平台建设的经验,孙寅认为,当前这个技术时代,不管企业规模大或小,都建议不要绕开开源自造轮子。如果企业规模小,直接用开源组件来解决企业痛点,如果企业规模大,可以改进或借鉴开源组件以解决性能和扩展性类问题,将各种开源技术组装、二次开发来解决复杂场景里的功能需求。
同时无论起步处于哪个阶段,都应该自订标准,因为开源组件仅是解决某一类问题的痛点,但标准是未来让组件协同,解决整体复杂场景问题的基础。
作者简介
孙寅,前百度资深架构师,曾负责百度运维平台多子系统;现小米资深架构师,负责小米运维体系基础架构、基础平台。
转载地址:http://kbupx.baihongyu.com/